
NDS #45 - 👋🏻 &num=100, cómo aprovecha Google nuestros datos, tips para mejorar Google Shopping, actualización de las quality raters y más...
Analizamos las novedades semanales del sector SEO e IA y sobre todo cómo nos puede afectar como consultores y te cuento mis vivencias y aprendizajes sentado varias horas al día frente a un monitor.

Me hace mucha ilusión saludarte en esta edición de la newsletter NDS, espero que cumpla tus expectativas y si es así, o si no lo es, estaré encantado de que me des feedback.
¿Quién es Javier Flores y qué es NDS? :)
👨💻 ¡Hola! Soy Javier Flores, consultor SEO en VisibilidadOn y creador de Notas de SEO (NDS), que estás leyendo ahora mismo. Esta newsletter nació en noviembre de 2024 como un espacio para compartir mis aprendizajes en SEO, marketing y negocios digitales. Si te gusta, dime qué opinas. Y si no... ¡también! 😉
🗂️ En el correo de hoy
1️⃣ La viñeta
2️⃣ Actualidad SEO
3️⃣ El parámetro &num=100
4️⃣ 8 errores comunes ante una caída de tráfico (logs + protocolo) | Guía de diagnóstico
5️⃣ Recursos / herramientas
6️⃣ Historia del SEO: "Backrub", el proyecto universitario que se convirtió en Google
👉 Aprende SEO, Google Ads y Analítica web
Una nueva clase grabada cada martes y jueves
Formaciones internas del equipo disponibles para ti
Profesores en activo en empresas o como consultores
Ejemplos reales de la agencia en todas las lecciones
EMPIEZA HOY - ACADEMIA VISIBILIDADON🫀 ¡Si te palpita el corazón cada vez que lees algo sobre SEO o tráfico en internet! Y estás buscando crecer en este sector, en VisibilidadOn siempre buscamos talento para ofrecer un mejor servicio a nuestros clientes y aprender y crecer todos juntos tanto profesional como personalmente... ¿Hablamos?
🖌️ La viñeta

📸Actualidad SEO
Noticias que lees en un ratillo.
[🌱 Sembrar visibilidad informacional en la era de algoritmos e IAGs] Muy interesante este artículo de Juan Antonio Castillejos de Human Level, que comparte que la clave para tener visibilidad ahora es centrarse en consultas "complejas" que la IA no puede resolver, creando contenido profundo con valor humano, E-E-A-T y autoridad temática para convertirnos en una fuente de referencia citable.
[🧰 Bookmarklet para extraer urls y títulos de AIO] Aina-Lluna Taylor comparte un bookmarklet que con un solo clic extrae todas las URLs y títulos de los resultados que menciona Google AI cuando realizas una búsqueda. Muy útil para revisar patrones en menciones y citas de AIO.
[🥸 Como usa Google los datos de usuarios en su favor] Siguen saliendo nuevos documentos del juicio antimonopolio de Google que revelan con más detalle cómo la empresa utiliza los datos de interacción del usuario (clics, hovers, etc.) en cada etapa del proceso de búsqueda para mejorar la calidad y la monetización, algo que ya intuíamos pero que ahora confirmamos. Además, se confirma que los datos de visitas de Chrome se usan como una señal de popularidad para el ranking, ¡como para querer vender el navegador que es su espía número uno!
[💻 RSL es un nuevo estándar de protocolo de licencias, abierto y descentralizado] Se ha lanzado el nuevo estándar web RSL, una evolución del robots.txt que permite a los editores establecer una compensación justa por el acceso y uso de sus contenidos por parte de la IA. Con este protocolo, las webs pueden elegir modelos de licencia como el "pago por rastreo" o el "pago por inferencia" (cuando la IA usa tu contenido para generar una respuesta), un estándar muy útil que puede apoyar a servicios como Pay per crawl de CloudFlare que ya vimos en la edición #34.
[🖊️ ¡Actualización de las Quality Raters!] Google ha actualizado sus directrices para que los Quality Raters evalúen ahora la calidad de las AI Overviews. Esto nos obliga como SEOs a crear contenido con un valor original muy superior al de las respuestas de la IA.
[🧰 LangExtract: una biblioteca de extracción de información impulsada por Gemini] Google ha presentado LangExtract, una nueva biblioteca de Python de código abierto diseñada para extraer información estructurada de grandes volúmenes de texto no estructurado utilizando LLMs como Gemini.
[🛒 Estado de search en Ecommerce] El equipo de Eleven ha lanzado un informe sobre el estado del Search en e-commerce para septiembre de 2025, abordando la preocupación sobre cómo la nueva búsqueda (más visual y con más IA) afecta al tráfico orgánico. Un recurso muy interesante para ponerse al día de los cambios que suceden en el search para ecommerces.
[🤖 Guía de SEO para IAs] Nico Bignu cofounder de LLMO Metrics (en próximas ediciones tendremos una review completa de esta tool) me hacía llegar esta guía de SEO para IAs muy interesante y de la que podemos sacar algunos accionables apra nuestras estrategias de SEO.
[🛒 4 TIPS para mejorar tu feed de Google Shopping] Un post interesante de mi compañero Lucas Arroyo para mejorar tu visibilidad en Google Shopping donde la clave es optimizar tu feed, ya que Google lo ordena según señales como el CTR. Añade el uso y la estacionalidad a los títulos, actualiza la validez de los precios y enriquece el schema con GTIN y opiniones para aumentar la visibilidad y los clics.
[📺 Directo de máster SEO VON con Josep] Esta semana Josep y yo hicimos un directo para explicar un poco mejor el máster y cómo lo enfocaremos y resolver dudas, sino pudiste verlo, te lo dejo debajo y cualquier duda nos puedes comentar.
Personalmente estoy muy ilusionado con este proyecto de máster, que este año será un poco ensayo y error, pero creo que la forma de enfocarlo 100% práctica puede sumar mucho a la formación de nuevos consultores.
Os dejo por aquí la presentación que vimos en el directo con todos los documentos y fuentes mencionadas.
[❌ El tráfico LLMs NO convierte mejor según este estudio] Semana nueva, estudio nuevo. En contra de lo que dice Google y de lo que yo mismo he visto en proyectos propios, este estudio (que se hizo en 54 sitios) desmiente que el tráfico LLMs convierta mejor. No estoy de acuerdo con eso, pero SI estoy de acuerdo y quiero recalcar que el tráfico LLMs de los sitios analizados fue de sólo el 1% frente al resto de tráfico orgánico de buscadores.
👨🎓EL parámetro &num=100
Esta semana ha estado un poco revuelta por la desaparición del parámetro &num=100, ¿qué es esto y qué significa?
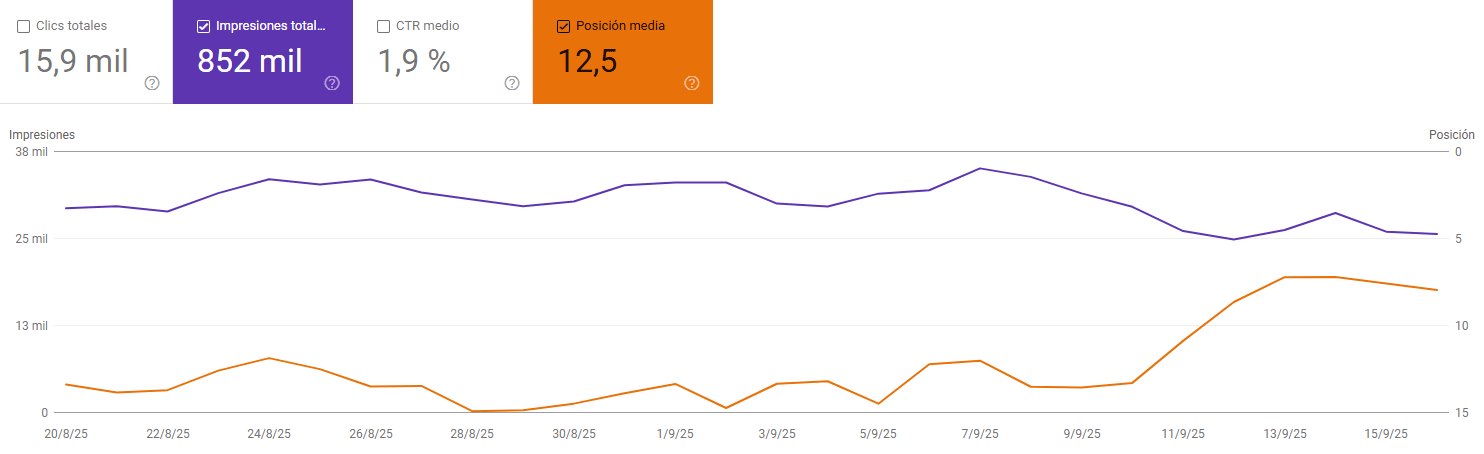
Antes, un ejemplo de cómo van a cambiar las gráficas en Google Search Console:
Las impresiones bajan porque ya no se contabilizan las de esas 100 primeras posiciones
La posición media suben, porque ya no se tienen en cuenta las kws de posiciones de más de 20
¿Qué es el parámetro &num=100?
Bien, es un “simple” parámetro que podíamos añadir a la URL de los resultados de Google y de esta forma “forzábamos” a Google a mostrarnos 100 resultados en lugar de 10, esto, que puede parecer algo trivial, para herramientas de tracking como Semrush, aHrefs y similares es un cambio significativo.
A partir de ahora “no se podrá” recopilar la posición de kws más allá de la página 2, es decir, tendremos menos visibilidad de una kw que empecemos a posicionar y no podremos ver su clasificación hasta que esté en TOP 20.
Para recopilar los mismos 100 resultados, las herramientas deben realizar 10 solicitudes separadas, navegando a través de las páginas de resultados de búsqueda (SERPs) una por una.
¿Por qué hace Google este cambio?
La decisión de Google de eliminar esta funcionalidad está impulsada por una confluencia de factores estratégicos, principalmente defensivos, destinados a proteger su ecosistema de datos y su posición en el mercado. Y quizás favorecer la llegada de Mode AI mientras bloquea el acceso a datos a “competidores” como ChatGPT, Perplexity…
Puede que Google tenga en mente activar una API (ya tiene una) de pago para poder monetizar el acceso a estos resultados ahora que se ha visto obligada por ley a compartir los datos de su BD, o que esté preparando el terreno bloqueando a competidores ante la llegada de Mode AI.
Combatir el scraping agresivo
La motivación principal es frenar el scraping automatizado e intensivo en recursos de sus resultados de búsqueda. Los términos de servicio de Google prohíben explícitamente el tráfico generado por máquinas, ya que consume una cantidad significativa de recursos de sus servidores y puede interferir con la calidad del servicio para los usuarios humanos. Al hacer que el scraping sea 10 veces menos eficiente, Google aumenta drásticamente el costo y la dificultad de esta práctica, desincentivando a los actores que dependen de la extracción masiva de datos.
El auge de la IA
El momento de este cambio está intrínsecamente ligado a la explosión de herramientas de inteligencia artificial y modelos de lenguaje grandes (LLMs). Estos sistemas a menudo dependen de enormes cantidades de datos extraídos de las SERP de Google para entrenar sus modelos y proporcionar respuestas en tiempo real. En efecto, competidores potenciales estaban utilizando el propio índice de Google, su activo más valioso, para construir productos que compiten directamente con la Búsqueda de Google. Las herramientas de SEO, en este contexto, pueden ser vistas como un daño colateral en una batalla estratégica mucho más grande por el futuro del descubrimiento de información.
Recuperar el control de los datos y la monetización
Al hacer que el scraping sea prohibitivamente caro, Google reafirma el control sobre su ecosistema de datos. Este movimiento ha intensificado la especulación y la demanda en la industria de una API de búsqueda oficial y de pago. Una API de este tipo permitiría a Google monetizar directamente el acceso a sus datos, proporcionando una vía legítima y sostenible para que las herramientas obtengan la información que necesitan, pero en los términos de Google y a su precio.
Cambio en las métricas que veremos en las reuniones de KPIs
Con la eliminación del parámetro &num=100, este comportamiento de los bots se ha detenido abruptamente, lo que ha llevado a una "limpieza" de los datos de GSC. Esto juega en nuestro beneficio, porque ahora nos damos cuenta que de esas impresiones muchas eran generadas por bots, crawlers de herramientas de rankings, etc…
Caída de las impresiones: La razón por la que las impresiones han disminuido drásticamente es que millones de estas impresiones artificiales de bots para resultados de búsqueda profundos (posiciones 20-100) han desaparecido de los informes.
"Mejora" de la posición media: La posición media en GSC se calcula tomando la posición más alta de un sitio para una consulta cada vez que se registra una impresión. Al eliminar el enorme volumen de impresiones de posiciones bajas (por ejemplo, 45, 67, 85), el conjunto de datos utilizado para el cálculo se inclina ahora hacia las posiciones más altas que los usuarios humanos ven con más frecuencia.
¡Te lo resumo! ¡No te asustes!
No hay que preocuparse, el rendimiento real no se ve afectado: Los clics, el tráfico y las conversiones de los sitios web de los clientes no han cambiado. La actualización solo ha afectado a la metodología de medición, no a los resultados subyacentes.
Los datos de GSC son ahora más precisos: La eliminación del "ruido" de los bots ha resultado en métricas de impresiones y posición media que reflejan con mayor precisión el comportamiento de los usuarios humanos.
El seguimiento de rankings ha evolucionado: La era del seguimiento masivo y profundo de palabras clave ha terminado.
El enfoque debe estar (siempre habría debido estar) en los resultados de negocio: Este cambio obliga a la industria que hasta ahora no lo hacía a elevar la conversación más allá de los rankings, y poner foco en los leads, conversiones, ingresos, ROI y CPA.
📺 8 errores comunes ante una caída de tráfico (logs + protocolo) | Guía de diagnóstico
🧰Herramientas / recursos
Te dejo una nueva herramienta que preparé para el curso de Logs que lanzaremos en la Academia de VisibilidadOn, es un analizador de logs.

🏛️Historia del SEO: "Backrub", el proyecto universitario que se convirtió en Google
Hoy en día hablamos de Google como si siempre hubiera estado ahí, dominando internet desde el principio de los tiempos. Pero antes de ser el gigante que conocemos, Google fue un proyecto de investigación universitario con un nombre bastante peculiar: Backrub.
Corría el año 1996 en la Universidad de Stanford. Mientras buscadores como AltaVista o Lycos luchaban por la dominación basando sus rankings en la densidad de palabras clave (lo que dio pie al salvaje oeste del keyword stuffing), dos estudiantes de doctorado, Larry Page y Sergey Brin, tuvieron una idea radicalmente distinta.
Su proyecto, Backrub, no se centraba en cuántas veces una página repetía un término, sino en algo mucho más ingenioso: analizar los enlaces que apuntaban hacia ella. El nombre "Backrub" (masaje de espalda) era un juego de palabras con el concepto de analizar los "backlinks" (enlaces entrantes) de una web.

La idea era simple pero revolucionaria: cada enlace desde una página A hacia una página B era considerado un "voto" de confianza. No todos los votos valían lo mismo; un enlace desde una página importante (como la de la propia universidad) valía mucho más que uno desde una página desconocida. Este sistema de reputación fue el germen del famoso algoritmo PageRank.
Mientras la competencia se ahogaba en resultados irrelevantes y spam, Backrub ofrecía resultados sorprendentemente precisos. Si buscabas "Universidad de Stanford", el primer resultado era la web oficial, no una página llena de spam que repetía el término cien veces.
En 1997, Page y Brin decidieron que "Backrub" no sonaba como una empresa multimillonaria. Lo rebautizaron como Google, un juego de palabras con el término matemático "gúgol" (10100), que representaba su misión de organizar la inmensa cantidad de información de la web.
El resto, como se suele decir, es historia. Pero la lección de Backrub es la piedra angular del SEO moderno: la autoridad y la relevancia, demostradas a través de enlaces de calidad, siempre ganarán la partida a los atajos y la manipulación. Así que, la próxima vez que trabajes en una estrategia de link building, recuerda que estás honrando un proyecto universitario que, literalmente, cambió el mundo.
Estamos en contacto
Puedes encontrarme en Linkedin, Twitter, mi blog, en mi canal de Youtube o trabajando a diario en la Agencia VisibilidadOn
🤜🤛 Si quieres que escriba sobre un tema concreto, que analice alguna web en vivo, que pruebe alguna herramienta, patrocinar la newsletter o financiarme un viaje en moto por Europa ahora es el momento, ¡contáctame!
📚 Si te has perdido alguna publicación o quieres revisar las anteriores, tienes el archivo disponible online para tí.